SMART-PAIR
Predictive Agent Interaction Representation for SMART-Style Traffic Simulation
2026-04-01
The Baseline Architecture We Keep
SMART generator path
- Vectorized map tokens enter RoadNet.
- Agent motion tokens enter MotionNet.
- Temporal, interaction, and map-agent attention produce next-token distributions.
- Rollout samples or selects the next motion token autoregressively.

SMART-PAIR: Small Training-Time Addition

What changes?
- Use existing hidden states from the SMART agent decoder.
- Predict future interaction latents through a compact PAIR branch.
- Train with matched future targets and a shuffled-target control.
- Remove the PAIR branch at inference.
\mathcal{L}_{\text{PAIR}} = 2 - 2\cos\left(\hat{z}_{i,r},\operatorname{sg}(z^+_{i,r})\right)
Experiment Logic: Checkpoint First

The project should not scale new training until checkpoint trust and stress diagnosis are reproducible.
Baseline Smoke Results


Scope: 4 validation batches, batch size 2, one closed-loop rollout, same fixed prefix. This is a mechanics/trust table, not a paper-grade benchmark.
Focal Rollout Comparison: Lead-Braking Case
Ground truth
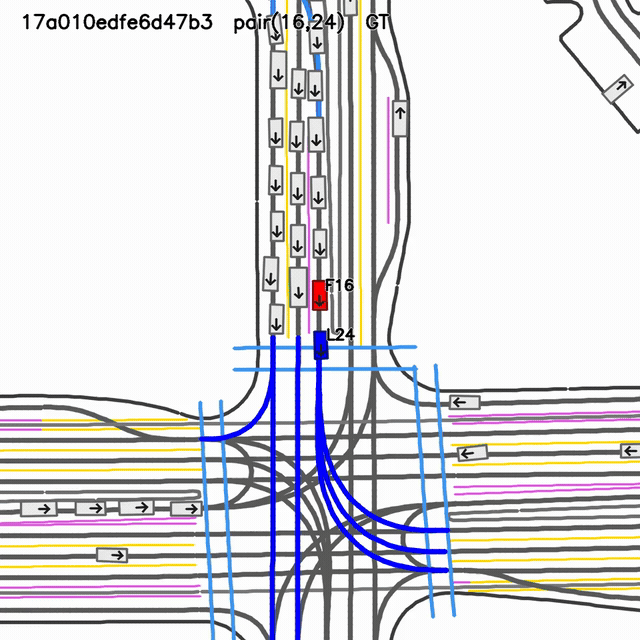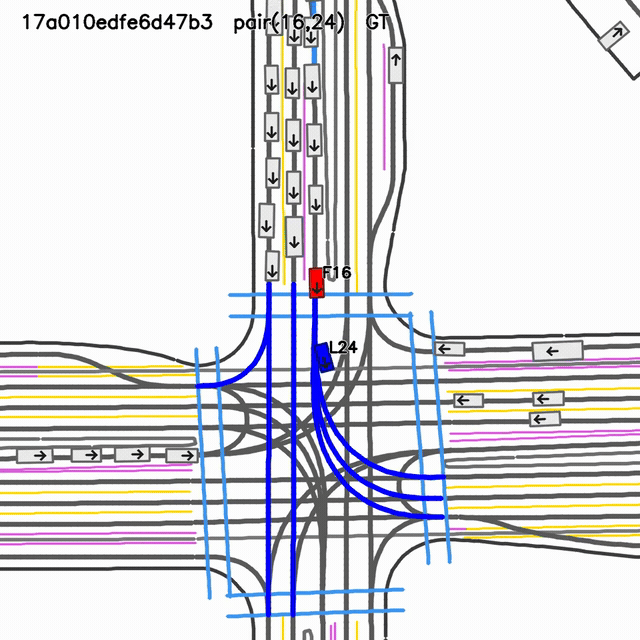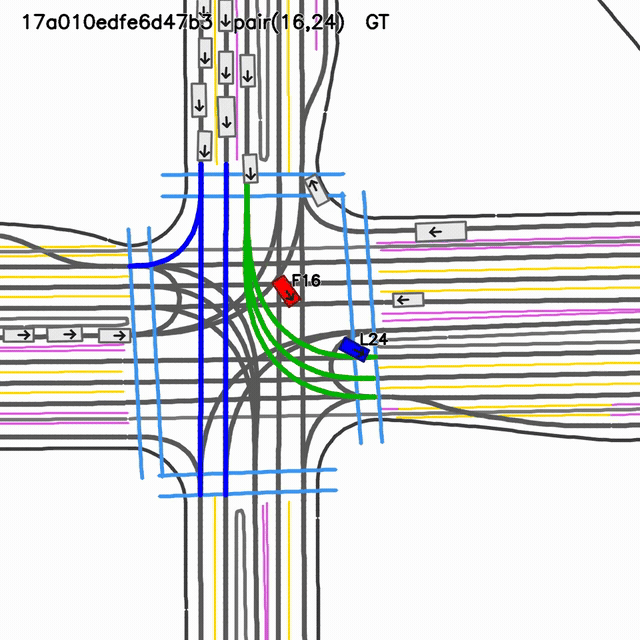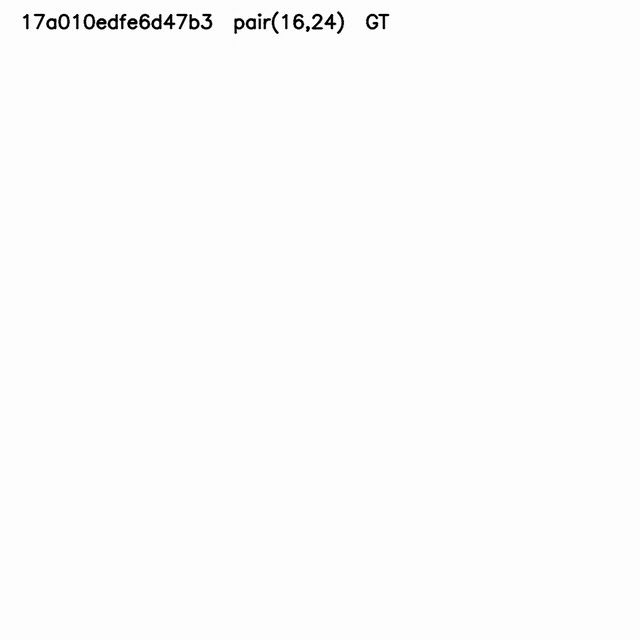
Logged scenario reference for case
17a010edfe6d47b3, follower 15, lead 22.
SMART-BC rollout
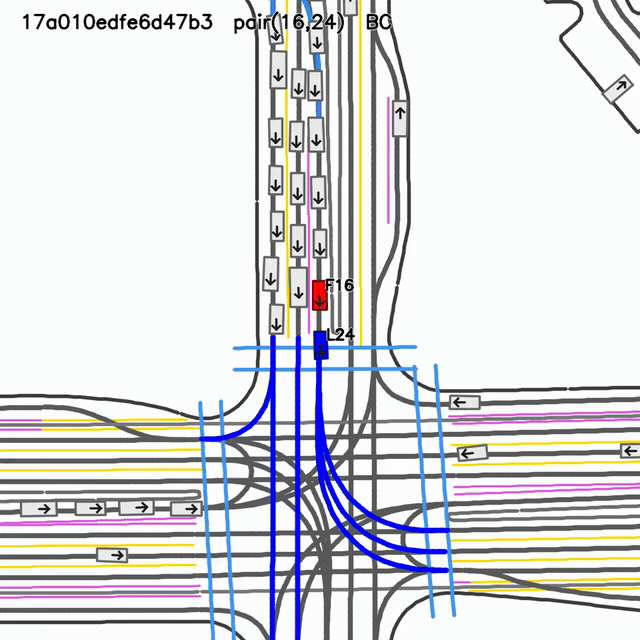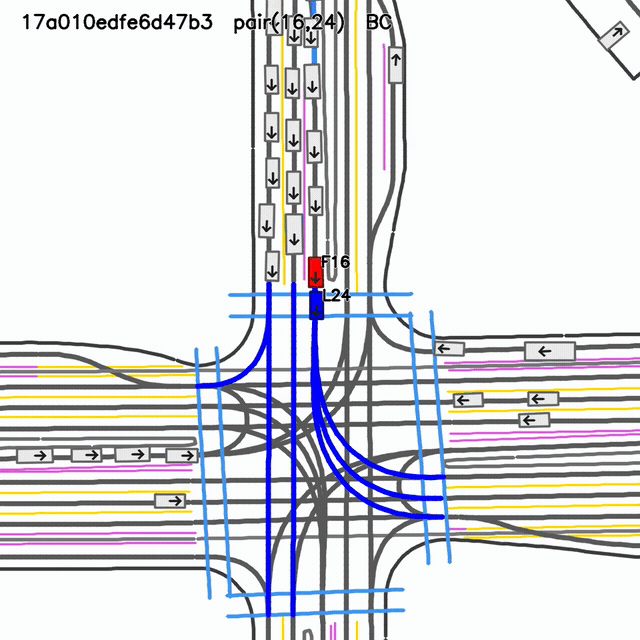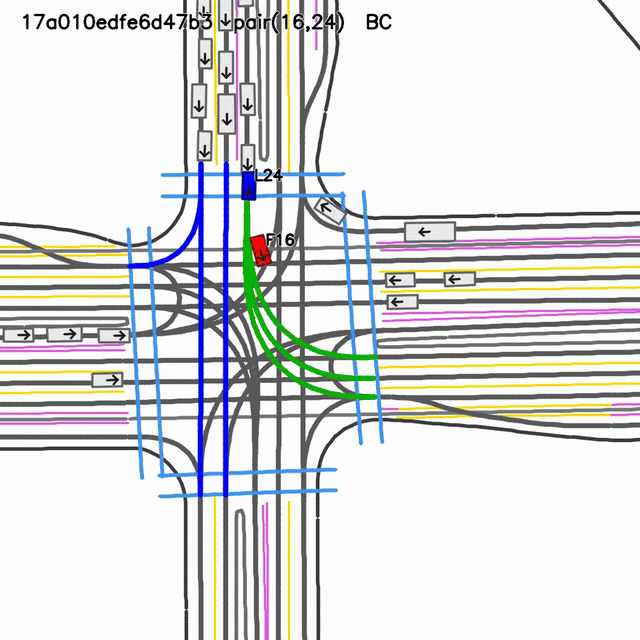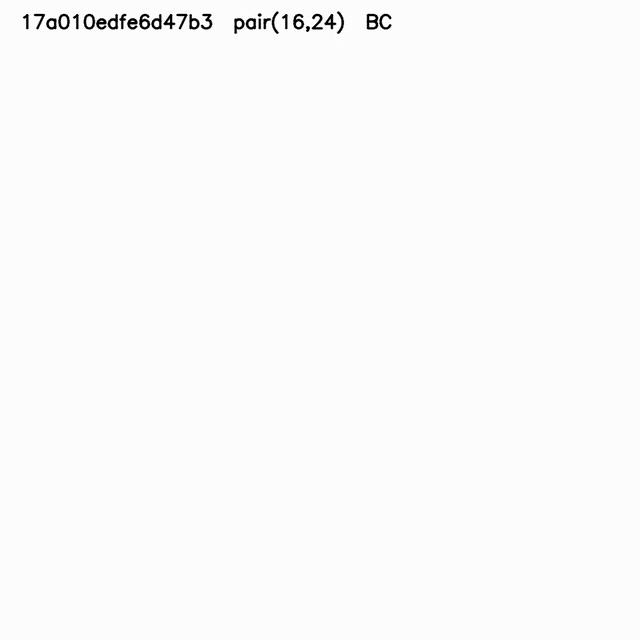
visual collision evidentselected-pair gap 5.21 mselected-pair TTC 2.62 s
Behavior-cloned SMART-tiny checkpoint. The pair metric does not capture every visible rollout collision, so this panel is treated as qualitative evidence.
SMART-CLSFT rollout
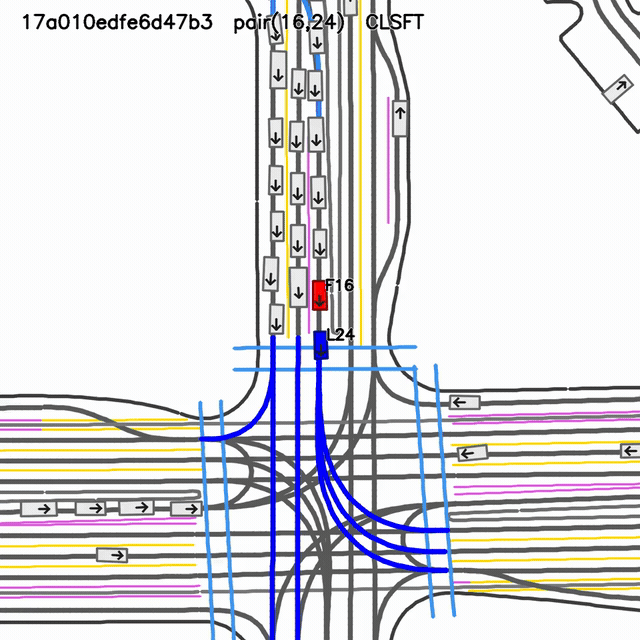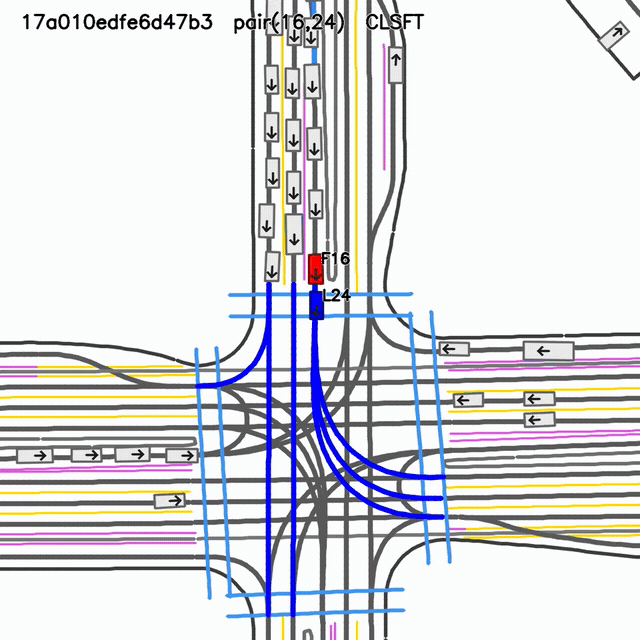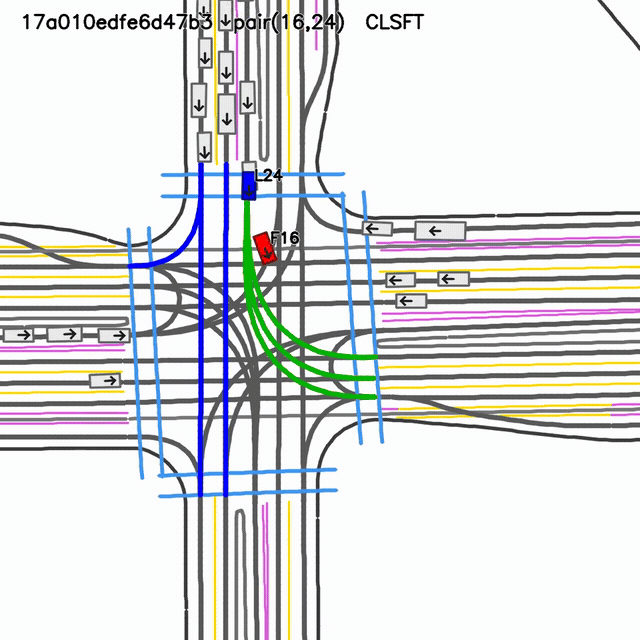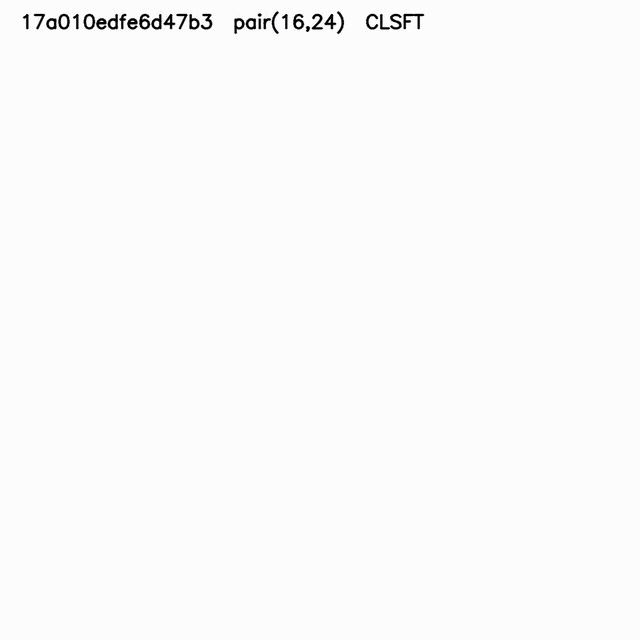
visual collision evidentselected-pair gap 0.19 mselected-pair TTC 0.017 s
Closed-loop fine-tuned reference checkpoint. The selected-pair metric and visual rollout both indicate a severe interaction failure.
GIFs are shown side-by-side for rapid visual comparison. Pair metrics are not global collision metrics; use this slide as qualitative diagnosis, not a benchmark claim.
First Stress Signal


Scope: 20 selected lead/follower pairs from 10 scenarios. This is diagnostic evidence only; visual inspection and larger coverage are still required.